Summary: Vision Transformers are Good Mask Auto-Labelers

In a new paper published on January 10th 2023, researchers from NVIDIA, Meta AI, FAIR, Fudan University, and Caltech, propose MAL: a Mask Auto-Labeler that has results that surpass those of current state of the art methods. This was a pretty interesting paper and I learned a lot about computer vision. I think the best way to learn any subject is to read a paper and just start by figuring out what all of the acronyms stand for… so many acronyms…
Let us summarize:
The Issue
Right now in computer vision, there is a lot of data that needs to be labeled and segmented for tasks such as detecting other cars, people, stop signs for autonomous driving, for example. A lot of this data is labeled and masked by humans and can result in a lot of errors if there is not quality control. Creating the COCO dataset required 55,000 hours of human work and this doesn’t guarantee that the labeling and masking is even correct.
Models that use data labeled by humans are considered fully supervised. However, there is another method called box-supervised learning, which Lan et al use in their work.
Methodology
The authors of this paper propose a model called MAL, Mask Auto-Labeler, which is essentially based on vision transformers. MAL is a two phase framework that has a mask auto-labeling phase and an instance segmentation training phase. From what I understand, this means that MAL generates the masks for input images and then the training (second) phase consists of training well known vision models to do image segmentation tasks using the MAL generated masks and see how they perform compared to their fully supervised versions.
Why RoI
Before we get into anything, let’s discuss the input data. Previous research on the topic of box-supervised training has used entire images, but MAL uses RoI (Region of Interest) images. It’s beneficial to use RoI images in this scenario for two reasons: 1. RoI images are good at handling small objects because the images are already enlarged and this can avoid issues caused by low resolution. 2. RoI images allow MAL to focus on the segmentation task on hand— this prevents the model from becoming distracted with tasks such as object detection. Here is an example of an RoI image. I was confused for some time on the difference between RoI and bounding boxes— they are not the same! Bounding boxes create the smallest box possible around an object, an RoI is a hypothetical area that is usually denoted with a box in other research papers and blogs.

How to get RoI
Once the RoI is obtained, the model has a zoomed in image of what needs to be segmented and it doesn’t have to look for other objects in the image to be segmented. In order to get the RoI, bounding boxes are randomly expanded to include background pixels, where negative bags are chosen from expanded rows and columns (later on this). This is an essential method for MAL, because it will otherwise learn trivial solutions and generated masks will fill the entire bounding box.
MAL Architecture
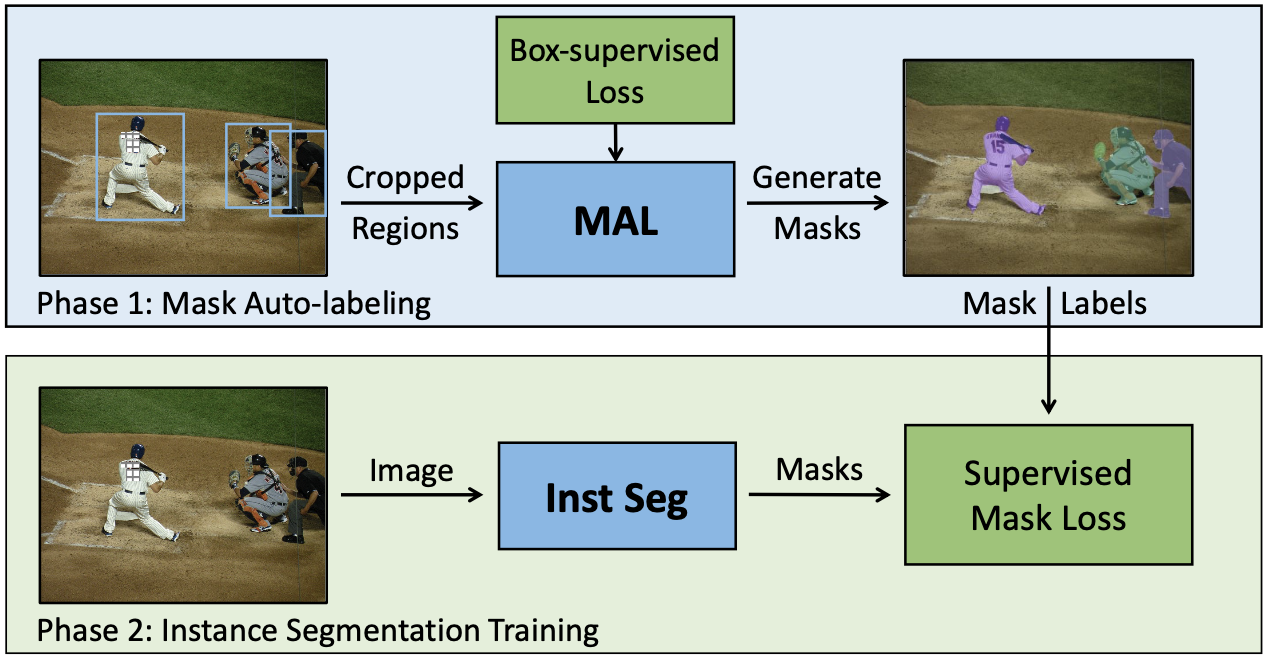
The MAL model consists of two symmetric networks: an image encoder and a mask decoder. The image encoder is a standard Vision Transformer (ViT). Some of the ViT’s that were used for comparison were: 1. ConvNeXts with Cascade R-CNN 2. Swin Transformers with Mask2Former 3. ResNets and ResNeXts with SOLOv2 The mask decoder is a simple attention based network inspired by YOLACT, a real-time instance segmentation model. Loss is measured with Multiple Instance Learning (MIL) loss. Once the mask is generated, each pixel in the output has a respective mask score. Within the image, each row/ column of pixels is considered to be a bag. Each bag will be positive or negative depending on the overall mask score of the pixels in that row/ column. Don’t quote me on this lol. My guess is that negative bags are considered to be outside of the mask and positive bags denote the RoI within bounds.
Results
The authors of this paper found that the instance segmentation models that they used with the MAL generated masks achieved up to 97.4% of their fully supervised performance on the COCO and LVIS datasets.
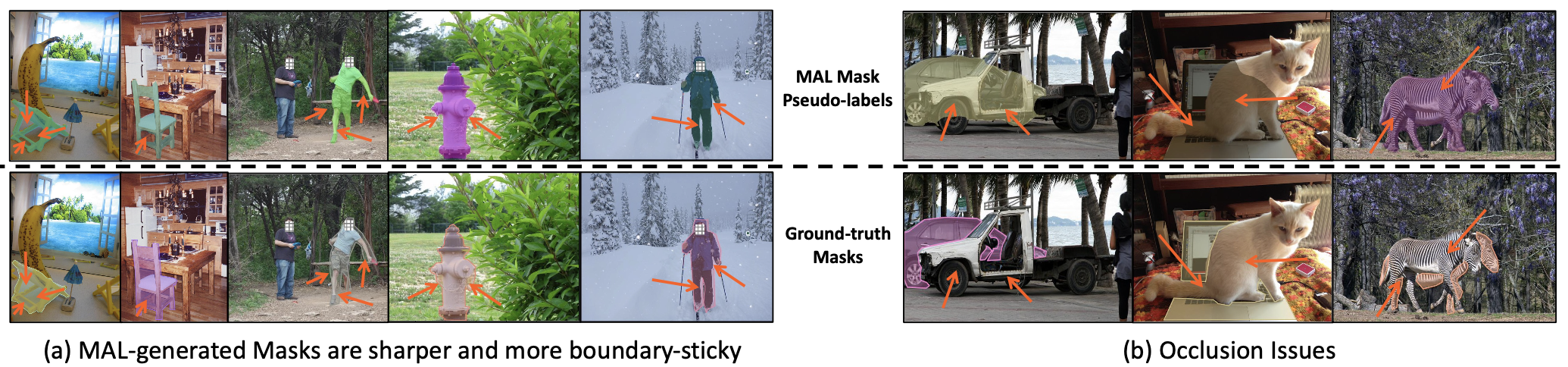
Overall, this approach narrows down the error gap between box-supervised and fully-supervised approaches. Currently, MAL outperforms all state-of-the-art box-supervised instance segmentation methods by a significant margin. Future work involves improving the model where there are overlapping RoI’s (occlusion issue).